

Backups towards Docker
Now that we handle Docker more or less adequately, and that we have instantiated a few services on our server with it, the system begins to fill up with data and configurations. As we have seen, all this data that we want to persist is linked from the service with our host through the use of volumes or bind mounts. Faced with this more or less organized increase, we are faced with the problem of being able to lose all the work done to date if a catastrophe occurs on our server.
Today we are going to see how to be able to store all this data in secondary storage, or even in a cloud service and keep one or more backup copies in order to revive a service in the event of any critical failure.
Duplicati
Among all the services that I have tried to create backup copies, I prefer Duplicati because it has all the requirements I need and some more:
- Supports file and folder encryption using AES-256 encryption.
- It has both a Web interface and a command line for the total management of the service.
- Allows to host backups very simply remotely (this includes protocols such as FTP, WebDAV, SSH,… or clouds such as Microsoft OneDrive, Amazon S3, Google Drive,…).
- Incremental backups, with which we can save a huge amount of space by saving only the changes made since the previous load.
- Planner to make backup copies when we are interested.
- Uses deduplication technology. Duplicati parses the content of files and stores blocks of data. Because of that, Duplicati will find duplicate files and similar content and store them only once in the backup. As Duplicati parses the contents of files, it can handle situations very well if files and folders are moved or renamed. Since the content does not change, the next backup will be small.
- Smart backups: Save backups gradually over time, and dispose of old ones. Saving a backup copy of the last 7 days, another copy each of the last 4 weeks and a last copy each of the 12 months. But we can also mark another type of retention if we are more interested in it.
- Allows automatic updates. Although in my case, I will use Ouroboros to keep the Docker container updated in which we are going to instantiate it.
On the contrary, it presents a series of drawbacks, which for now have not been “solved”.
- It does not have a powerful notification system. You can hardly send Emails or HTTP messages to events that happens when making backups.
- If we lose the encryption key, all the backup copies that use this key will be useless.
- If for any reason the Duplicati database becomes corrupted, it is very possible that the backup copies will be unusable in that instance. To fix this, you would have to reinstall Duplicati with a fresh installation and restore a backup of your configuration.
- Backup copies can only be managed, made or restored with Duplicati. It uses its own backup system and cannot be opened with another application or file manager.
Preparation
When making backup copies, not all data should be preserved. It is something that must be thought through carefully and analyzed in the context of each service. For example, I am a bit reluctant to save logs (logs), since personally, it is not something that I am interested in keeping. But it can still be important for another person to, for example, detect possible errors or improvements.
Although Duplicati allows a great variety of filters, selection of folders or even ignoring files and folders, in my opinion, the ideal thing is to have the information of the Docker containers divided into two or three folders according to the criticality of your data. This means that I do not have to modify the configuration of the backup copies in Duplicati if I add or remove a container and, in this way, I have the information located due to its criticality. So, for example, we can organize folders in this way:
/
├ docker
│ ├ etc # Folder where I keep the important volumes that I want to keep
│ │ ├ container1_config
│ │ ├ container1_data
│ │ ├ container2_config
│ │ └ ...
│ └ tmp # Folder where I save the volumes with logs or temporary files
│ ├ container1_log
│ ├ container2_log
│ ├ container2_cache
│ └ ...
└ ...
This is just an option, but you can order the volume folders as you are most interested or use the filters that Duplicati brings if it is more useful for your system.
The services themselves, many times, allow you to configure the folders where your data is stored and thus be able to separate what we want to save from what is not important. After the service is configured, it is necessary to reconfigure the associated volumes.
Installation
As on other occasions, we are going to instantiate the service using Docker. The Duplicati container gives us does not have much complexity, we just have to execute the following command in our terminal changing a couple of parameters.
$ docker run -d --name=duplicati --hostname=duplicati -e TZ=Europe/Madrid --net=bridge -p 8200:8200 -v /docker/etc/duplicati_data:/data -v /docker/backups:/backups -v /docker/etc:/source --restart always duplicati/duplicati
You also have an example for Docker Compose here.
As you can see, I’m going to use the host folder /docker/backups folder to save the local backups and the folder /docker/etc as a data source for backups. As is common in Docker, you can link all the folders that you think are appropriate with the container to make the backups as you like.
Note: You can also see how I include the Duplicati configuration folder among the files that I am going to save by putting it inside the data source folder with
-v /docker/etc/duplicati_data:/data.
Once the Duplicati service is instantiated. You can access its Web manager from http://IPDETUSERVIDOR:8200.
Setting up backups
Once the preparations have been made and Duplicati has been installed, we can now create our automated backup system.
Once inside the Duplicati management page, we click on “Add backup” and “Configure new backup”.
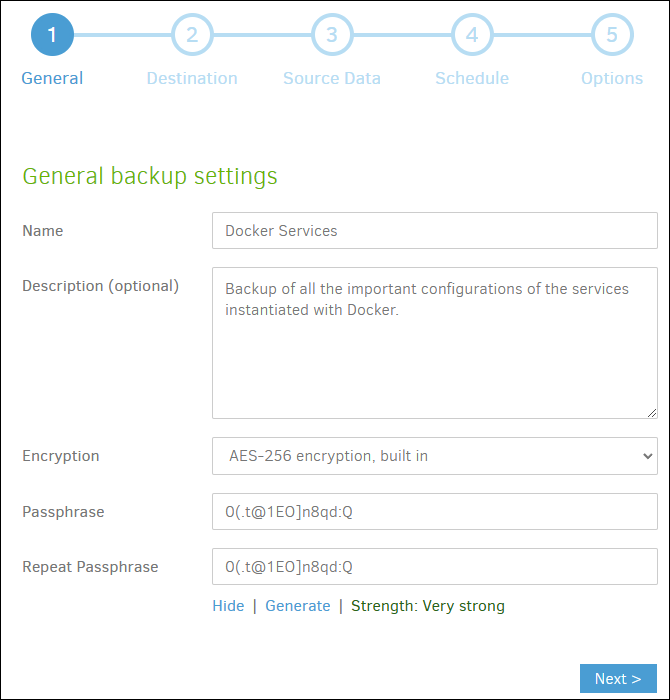
In the first step, we indicate a name and description that are reasonable and activate AES-256 encryption, this will protect the copied data. Generate or write a security phrase and write it down in a secret place, IT IS VERY IMPORTANT.
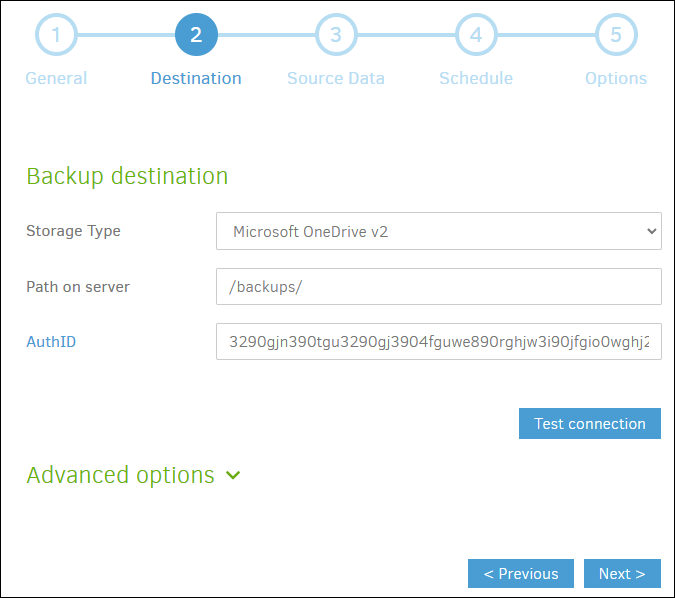
In the second step, we mark what we want to be the destination of the backup. In this example, we want the copies to end up in a personal cloud with Microsoft OneDrive, for this we will only have to log in to the service and indicate a destination folder.
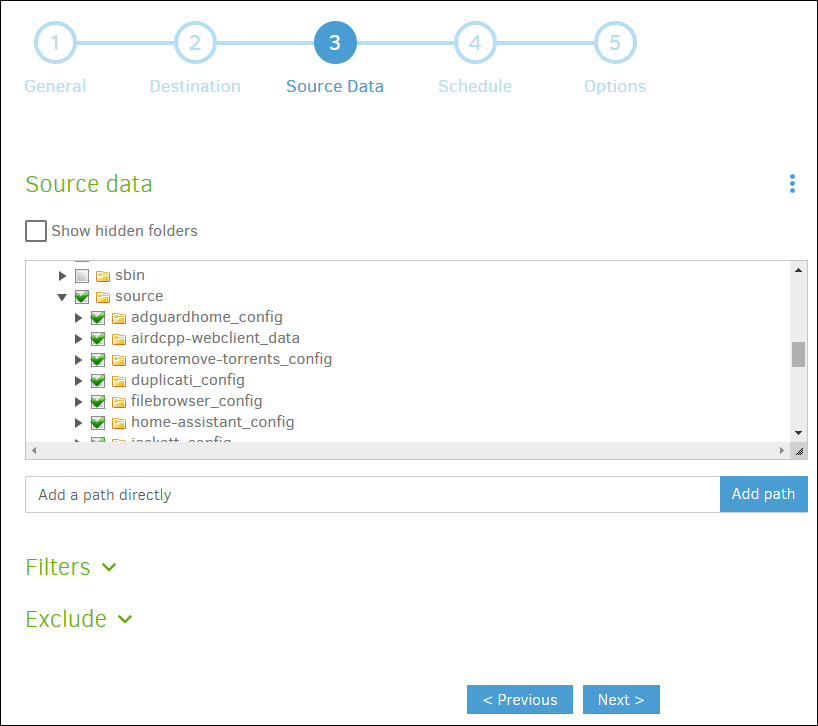
In the third step, we will configure the source data, we will do it by linking the host folder where we save the data on which we want to make backup copies with the source folder inside the Duplicati container, we select that folder as the source. Inside, we can see the folders on which the copy will be made.
We can make other configurations if desired, and even apply filters or exclusions.
In the fourth step we are going to configure a schedule in which to perform backups. In this case, I want the copy to run every day at 05:00.
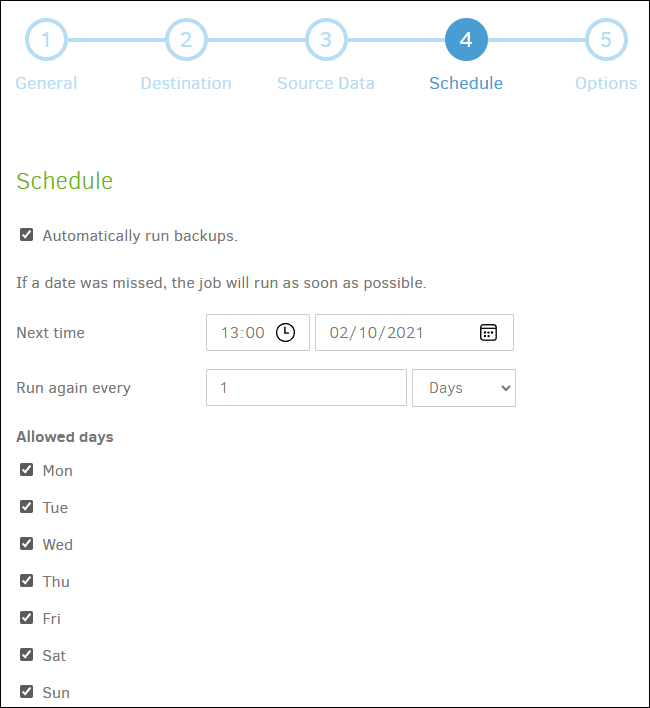
In the fifth step, other options are decided, such as the size of the volumes (blocks into which the backup will be divided), or what type of preservation is desired, with a retention of copies being recommended (although not required). intelligent. This configuration, like the others, will depend on the type of backup we want and the capacity of the destination.
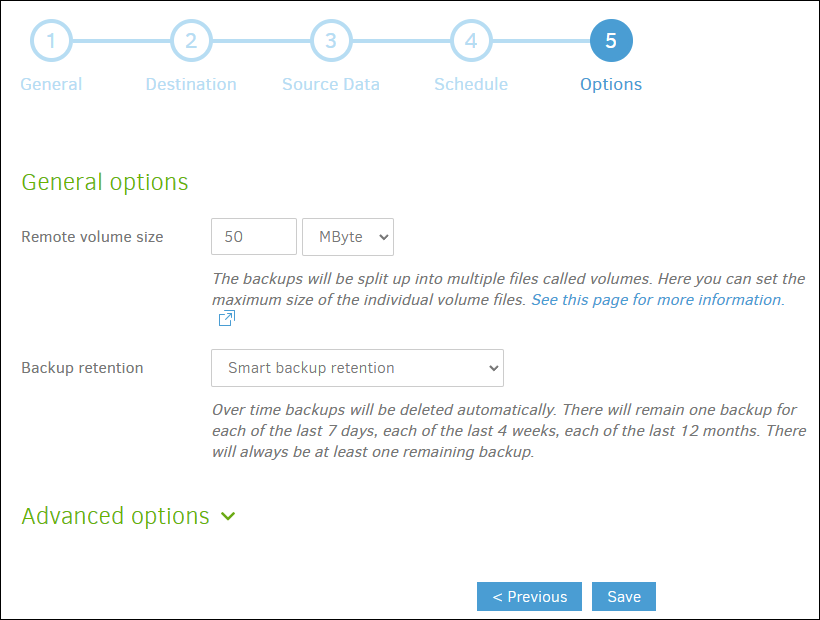
Once the configuration is saved, we can make a first backup to verify that everything works correctly.
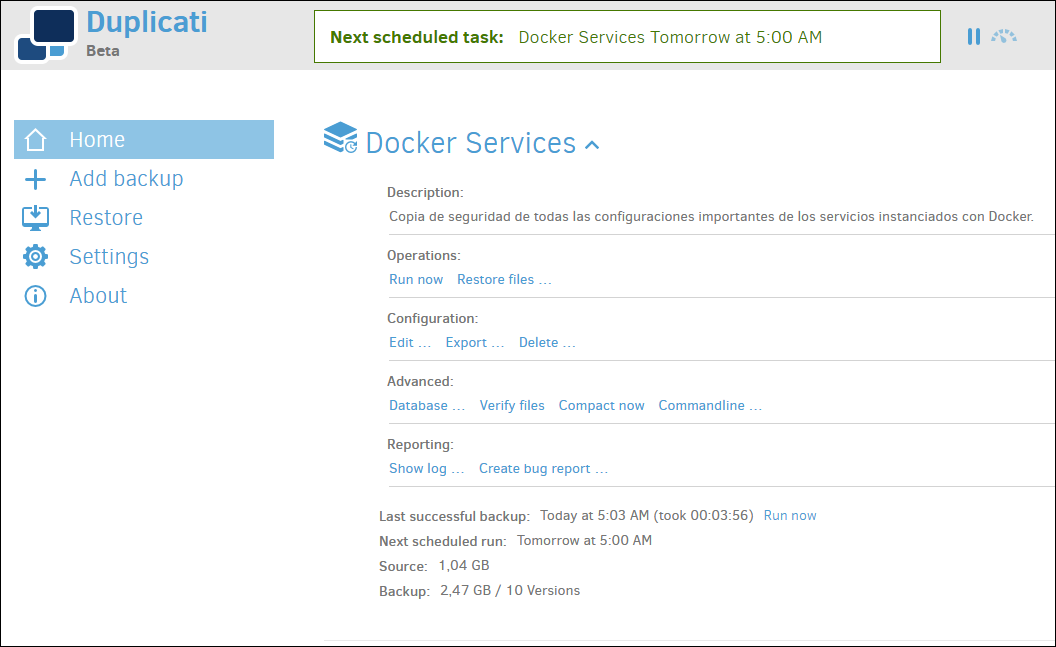
From the home screen, we will have all the information about the number of copies made, space occupied by them, upcoming executions, etc.
Restore Backups
Let’s imagine for a moment, that a catastrophe has occurred and we want to recover data from a backup copy. Duplicati allows us to restore backup copies incrementally if this has been configured and restore parts of that copy as files or folders separately.
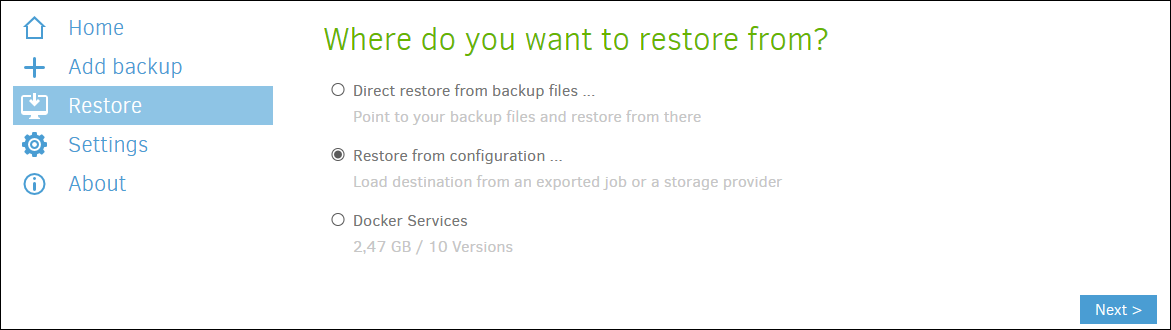
If the catastrophe is not so serious as to have destroyed Duplicati and its configuration, simply enter the Duplicati Web manager, click on the “Restore” menu, and select the configuration from which you want to recover (Docker Services in this article). Then, we select the data to recover and finally what we want to do with that data. For example, we can recover a file for a change that has broken a configuration of a service, to a previous version of it.

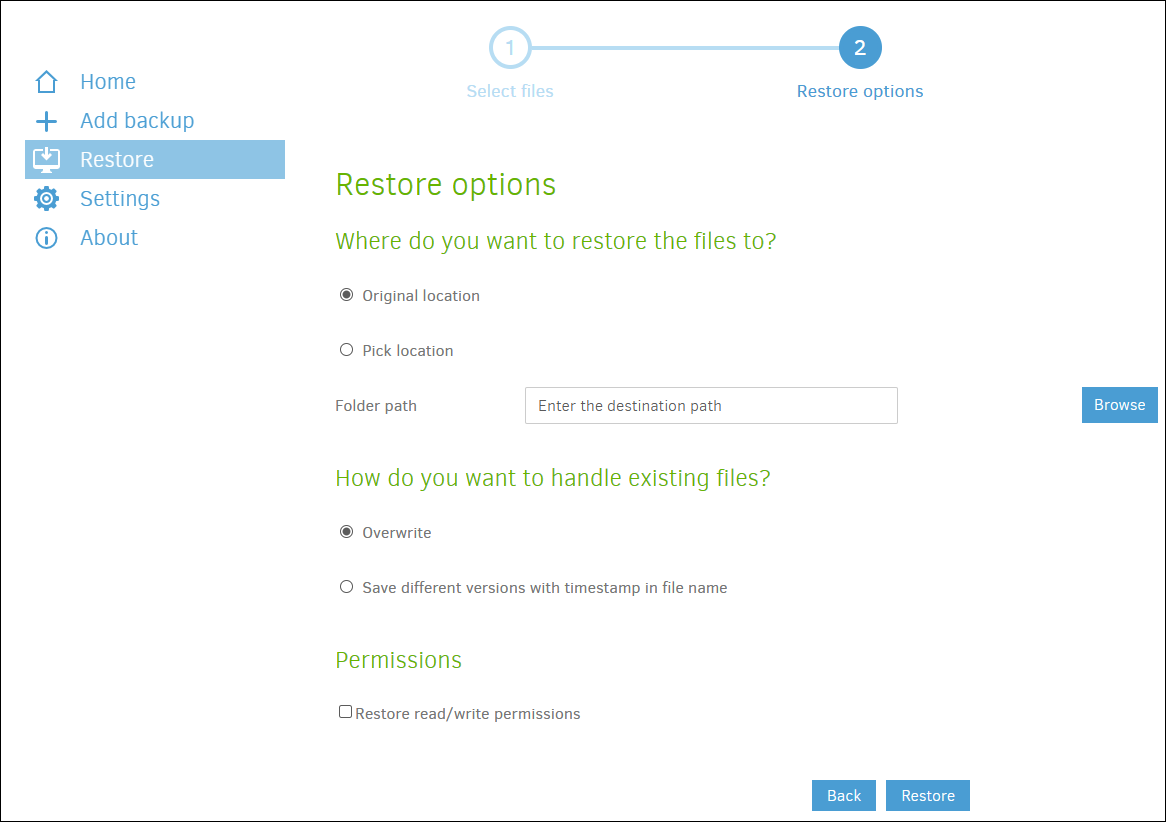
But, it can also happen that the catastrophe is total and the configuration of the server or Duplicati has been unusable. In order to restore a more “serious” copy from a site that we have not previously configured in Duplicati as it is a new installation, we can select “Restore directly from backup files…“, tell it that the copy is hosted, for example, in a cloud and from there, restore the data in the same way that I have commented in the previous paragraph.
With this thought in mind, we can make a backup copy of the Duplicati configuration and database, so if something serious happens, we can restore it later.
Conclusion
With what has been seen in this post, we should have several backup copies in an external storage or cloud that ensures certain recovery from disasters and small configuration changes that break the system or the services instantiated in Docker containers.
From here, and depending on your configuration in Duplicati, you will not have to touch the service much more. If you are installing new containers, you only have to take into account the directories where you create the volumes associated with them to create backup copies of the data that you really want to keep.
Feel free to ask or contribute your experience by following this article in the comments.
This and other articles complement the documentation of my GitHub repositories where all the configuration of my server and the home automation associated with my house are available.



